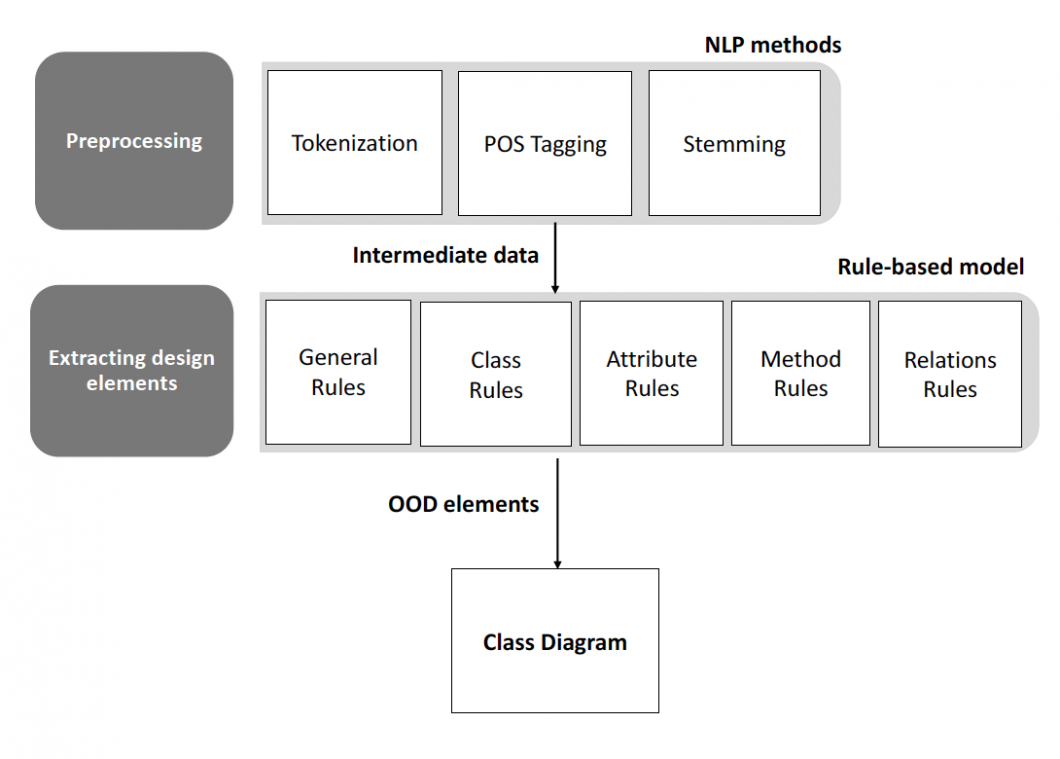
Yazılım gereksinim dokümanlarının kullanılarak, otomatik kaynak kod üretilmesi zor bir konu olsa da alanda çalışmalar mevcuttur. Doğal dil işleme teknikleri ve kural tabanlı yöntemler kullanılabilir. POS (Part of Speech Tagging) etiketleme (isim, sıfat, fiil, zamir, zarf bulma) burada kritiktir. Nesneye yönelik paradigma ile geliştirilecek bir sistemde, gereksinim dokümanlarındaki isimler (noun); aday sınıf ve özelliklerdir. Fazla geçen isimler muhtemelen sınıf adlarıdır. Aynı cümledeki isimler ve fiiller, sınıflara ait metotlar olabilir. Ozlem Aktas hocamla danışmanlığını birlikte yürüttüğümüz Fatma Bozyiğit hocamızın doktora çalışmasını başarıyla tamamladık. Yaptığımız çalışma sayesinde literatüre hem yeni bir veri kümesi kazandırdık hem de daha önce Türkçe’de hiç yapılmamış (cesaret edilmemiş) bir veri bilimi uygulaması geliştirdik. Sonraki çalışmalarda işbirliğine hazırız.
- Makale İsmi: Automatic concept identification of software requirements in Turkish
- Makale Adresi: https://lnkd.in/eUn73ZZ
- Veri kümesi: https://lnkd.in/eARcTWr
Deniz Kılınç