
Yapay Zeka benim yerime program yazabilir mi? Peki işimi elimden alabilir mi?
Tüm dünya genelinde Dar Yapay Zekâ (Artificial Narrow Intelligence — ANI) alanındaki uygulamaların sayısının hızlı şekilde artması ve başarılı ürünler ortaya konulması, bazen şaka gibi gelen ve uzak durduğumuz “gelecekte benim mesleğim de ortadan kalkacak mı?” sorusunu hepimize sordurmaya devam ediyor. Önce Github Copilot ile bayağı eğlendik. Sonra ChatGPT ile birlikte bu soru çok daha fazla sorulmaya başladı.
İlk defa dar yapay zeka (ANI — Artificial Narrow Intelligence) alanında “isviçre çakısı” gibi her alanda (sanat, bilim, doğa, mühendislik …) cevap veren ve/veya içerik üreten bir chatbot ile kaşılaştık ve elbette şaşkına döndük. Bir de yapay zeka çalışmalarını if-then-else bloğuna sıkıştırıp dalga geçen teknoloji çalışanları deyim yerindeyse dumur oldu.
Ancak yazılım geliştirme sürecini baştan sona ele alarak yorum yapan kimseyi maalesef göremedim.
Yazılım Verileri ve Yapay Zekâ (ANI) Çalışmaları
Bu noktaya nasıl geldiğimizi kısaca özetleme çalışalım. Lütfen sıkılmadan okumaya çalışın. Yazılım geliştirme yaşam döngüsünde (SDLC — Software Development Life Cycle) bir ANI uygulamasını eğitmek (ya da tanımlayıcı analiz yapabilmek) için kullanabileceğimiz verileri aşağıdaki gibi sıralamamız mümkün (SDLC ile ilgili bilgi almak için şu yazıyı okuyabilirsiniz).
- Kaynak kodlar
- Gereksinim dokümanları
- Tasarım dokümanları
- Hata (bug) iletim kayıtları
- Kaynak kod kontrol aracındaki kod değişiklik farkları/logları
- Test senaryoları
- Çevresel girdiler (programlama dili, paradigma, tecrübe vb.)
Yazılım Kaynak Kodları
Yazılım kaynak kodları üzerindeki ilk çalışmalar; kod büyülüğü ve kalitesi üzerine yapılmış. Koddaki satır sayısı, boşluklar, yorumlar, fonksiyonlar, parametreler, değişkenler, koşullar, döngüler vs. dikkate alınarak farklı ölçütler hesaplanmış. Statik kod analizi yöntemleri ile hesaplanan “Çevrimsel Karmaşıklık — Cyc.Comp.” bunlardan en eskisi diyebiliriz. Nesneye yönelik programlamama ile birlikte coupling ve cohesion gibi temel ölçütler referans alınarak RFC, DIT (Depth of Inheritance Tree), WMC (Weighted Methods per Class), CBO (Coupling Between Object Classes), LCOM gibi diğer ölçütler türetilmiş.
Yine kaynak kodlar ve çeşitli istatistik tabanlı hesaplamalar kullanılarak “yazılım emek ve süre kestirimi (software effort estimation — Örn; bu iş kaç adam-gün/saat sürer?)” yapılması uzun zamandır üzerinde çalışılan konulardan birisi. İşlev puanı, IFPUG (International Function Point Users Group), nesne puanı, senaryo puanı, COSMIC puan ve COCOMO hem akademide hem de endüstride kullanımları yaygın olan ölçütlerden bazıları.
Kaynak kodun “yazarının bulunması” ANI alanındaki gösterişli çalışmalardan birisi. Yazılım geliştiricilerin program yazma alışkanlıkları/stilleri, isimlendirme seçimleri, tasarım yaklaşımları, fonksiyon başına yazdıkları ortalama satır sayıları, yorum satırı kullanma tarzları vb. birçok değişken girdi olarak kullanılarak bir örüntü çıkartılmaya veya model eğitilmeye çalışılıyor.
Kaynak kodlar arasında “benzerlik (similarity) bulma”, güvenlik kategorisindeki (plagiarism) önemli konulardan birisi. Doğal dil işleme teknikleri (ön işleme, gövdeleme vb.) ve yaklaşık metin benzerliği bulma algoritmaları (Levenshtein, Jaccard, Jaro, N-gram vb.) ya da yeni nesil Derin Öğrenme mimarileri kullanılıyor.
Hata Bildirim Kayıtları
Hata kayıtlarına ait metinler ile kaynak kodların eşleştirilmesi üzerine de farklı çalışmalar mevcut. Örneğin girilen bir hatanın kaynak koddaki yerinin (hangi dosyada, sınıfta, fonksiyonda, satırda?) konumlanması yani “bug localization — hata konumlandırma” çok çalışılan konulardan birisi ve sektörde de kullanılıyor. İletilen bir hata kaydının yerinin otomatik olarak bulunması ya da olası kaynak kodların yazılımcıya önerilmesi yazılımcıların hayatlarını kolaylaştırıyor.
Gereksinimleri Anlama ve Tasarıma Geçiş
Gereksinim dokümanlarının kullanılarak, “otomatik kaynak kod üretilmesi” alandaki zor bir konu olsa da yapılan farklı çalışmalar mevcut. Bu çalışmalarda genelde doğal dil işleme teknikleri ve kural tabanlı yöntemler kullanılıyor. POS (Part-of-Speech Tagging) etiketleme yani kelimelerin isim, sıfat, fiil, zamir ya da zarf olup olmadıklarını anlama bu noktada çok kritik. Örneğin, nesneye yönelik paradigma ile geliştirilen bir sistemde, gereksinim dokümanlarındaki isimler (noun) genelde aday sınıf ve özelliklerdir varsayımı ile yola çıkılıyor. Fazla geçen isimler muhtemelen sınıf adlarıdır. Aynı cümledeki isimler ve fiiller, sınıflara ait davranışlar (metot/fonksiyon) olabilir vb. kurallar ve yapay öğrenme modelleri kullanılarak kaynak kodlar otomatik üretilebilir.
Dr. Özlem Aktaş birlikte danışmanlığını yaptığımız Dr. Fatma Bozyiğit’in doktora çalışmasında Türkçe gereksinimlerde önemli bir yol kat ettik. Yaptığımız çalışma sayesinde literatüre hem yeni bir veri kümesi kazandırdık hem de daha önce Türkçe’de hiç yapılmamış (cesaret edilmemiş) bir ANI uygulaması geliştirdik. Uygulamanın basit görünümü aşağıdaki gibi
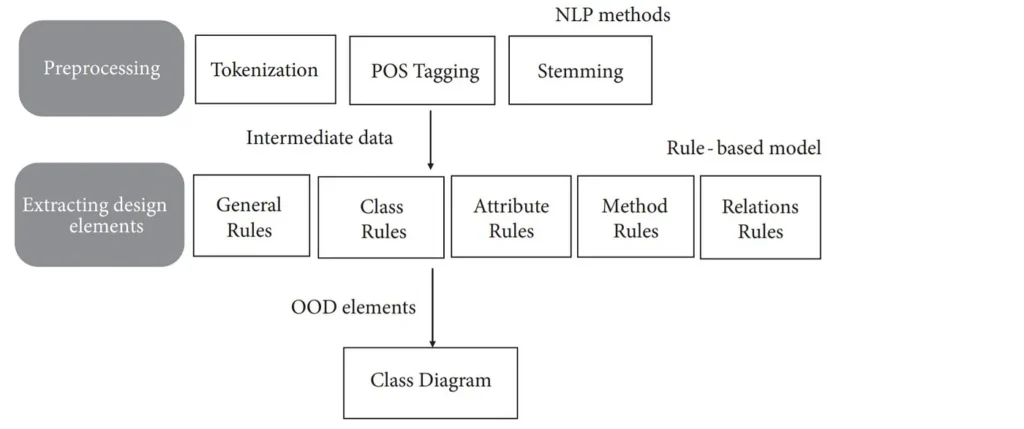
Yazılım Tasarımı ve Kod Üretme
Yeni yapılan bazı çalışmalarda GUI (Graphical User Interface) tarafında yapılan çizimler (wireframe, mock-up, protoipleme) görüntü işleme ve derin öğrenme modelleri kullanarak Frontend kodlarına (Örn: HTML, CSS, JS) otomatik olarak dönüştürülmüş. Aşağıda videosunu izleyebileceğiniz Pix2code bu çalışmalardan birisi …
Yazılım Testi
Yazılım test süreçlerinde de farklı ANI uygulamaları geliştirilmiş durumda. Örneğin koşturulan test senaryolarının önceliklendirilmesi ya da bu senaryoların azaltılması, hayatı kolaylaştıracak önemli uygulamalardan birisi diyebiliriz. Bu noktada tanımlayıcı ve istatistiksel analiz yöntemleri — LDA, LSI — , bilgi geri getirimi, doğal dil işleme ve metin işleme gibi yöntemlerin kullanıldığını görmekteyiz.
Sonuç ve Soru
Farklı SDLC aşamaları için yapılmış yüzlerce çalışma, tüm süreçlerde iyileştirmeyi ve toplam kaliteyi arttırmayı hedefliyor. Çalışmaların önemli bir bölümü henüz akademik tezgahtan mutfağa geçememiş durumda. Özellikle yazılım geliştirme (programlama) aşamasındaki süreci hızlandırabilecek (otomatikleştirecek) çalışmaların kendini göstermeye başlaması, yazılımcıların duymaktan kaçındığı bir soruyu bize zorunlu şekilde sorduruyor.
ANI (Dar Yapay Zeka) uygulamaları ya da sistemleri gerçekten çok akıllanıp insanlar gibi yazılım geliştirebilecekler mi? Yoksa daha kaliteli kod yazabilmemiz için asistanlık mı yapacaklar? Bu bir rüya mı yoksa kabus mu?

Kişisel Yorumlar ve Düşünceler
Yapay zeka kategorisindeki ANI uygulamalarının gelişim hızlarını ve yatırım yapılan alanları değerlendirdiğimde, önümüzdeki 15–20 yıllık sürede ANI uygulamalarının CASE (Computer Aided Software Engineering Tools) araçları gibi ciddi anlamda yaygınlaşacağını ve IDE ortamlarına entegre olacaklarını düşünüyorum. Kod yazma aşamasında ve derleme aşamasında yazılımcılara yol gösterecekler, (bu süreçte) kesinlikle yazılımcıların yerlerini almayacaklar.
Ancak rutin birçok iş/aşama ortadan kalkacak ya da daha hızlı tamamlanabilecek.
IDE’lerin (Integrated Development Environment) desteklediği otomatik kod parçacığı (code snippet) önerme süreci 5 yıl içerisinde yeni bir boyut kazanacak. Bu durum yazılımcılarda “wow etkisi” yaratacak ve onları heyecanlandıracak. Örneğin, Visual Studio için şu linke bakabilirsiniz. Aşağıda aynı sayfada yer alan örnek bir uygulamayı görüyorsunuz. Uygulamada bir kod parçası refactor (kodun yeniden yapılandırılması) edilirken, code snippet’ların bizi nasıl yönlendirdiği anlatılıyor.
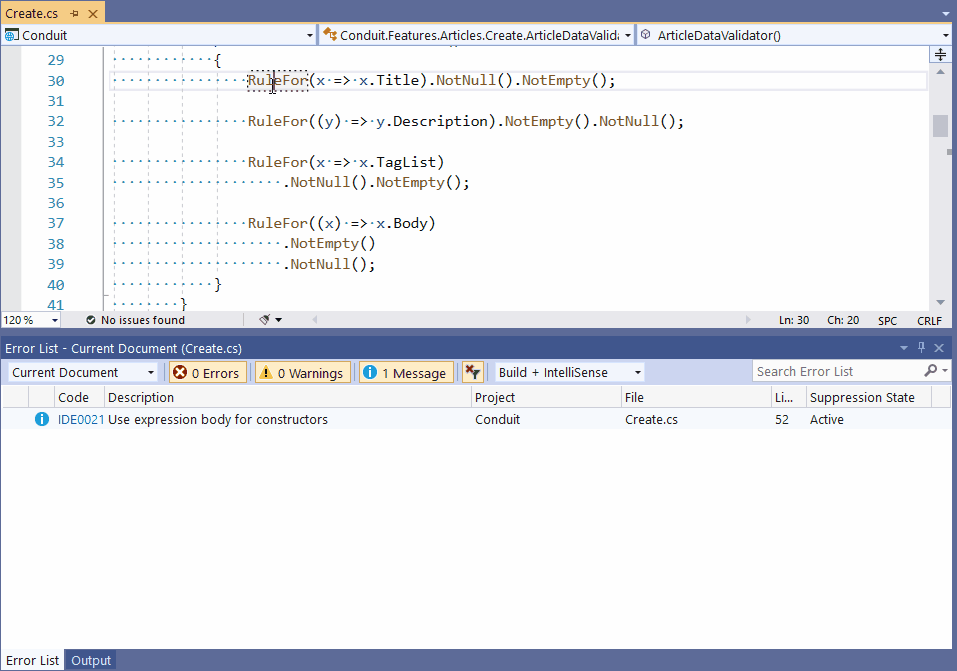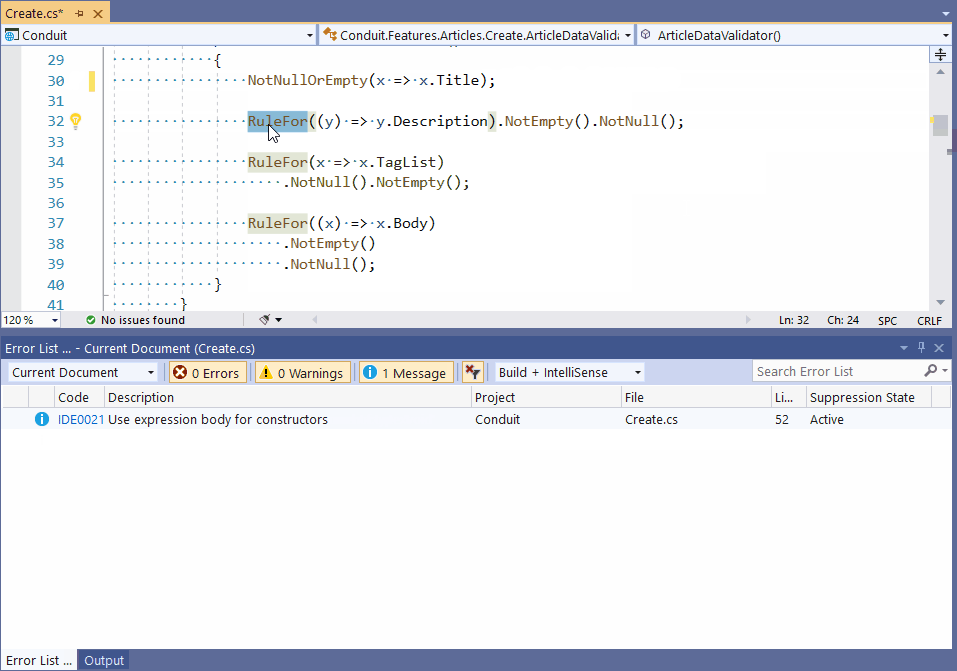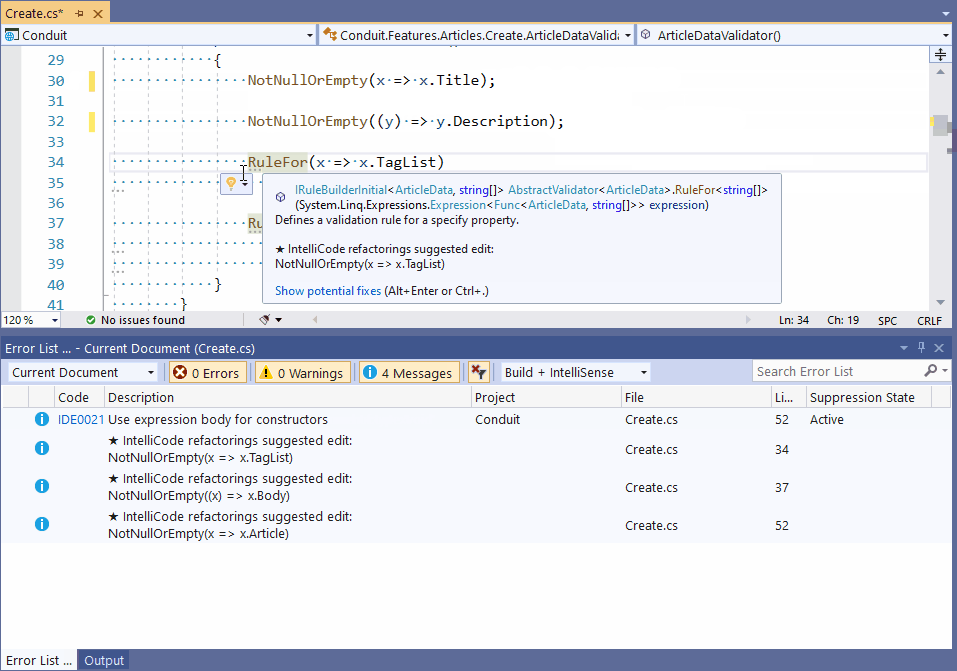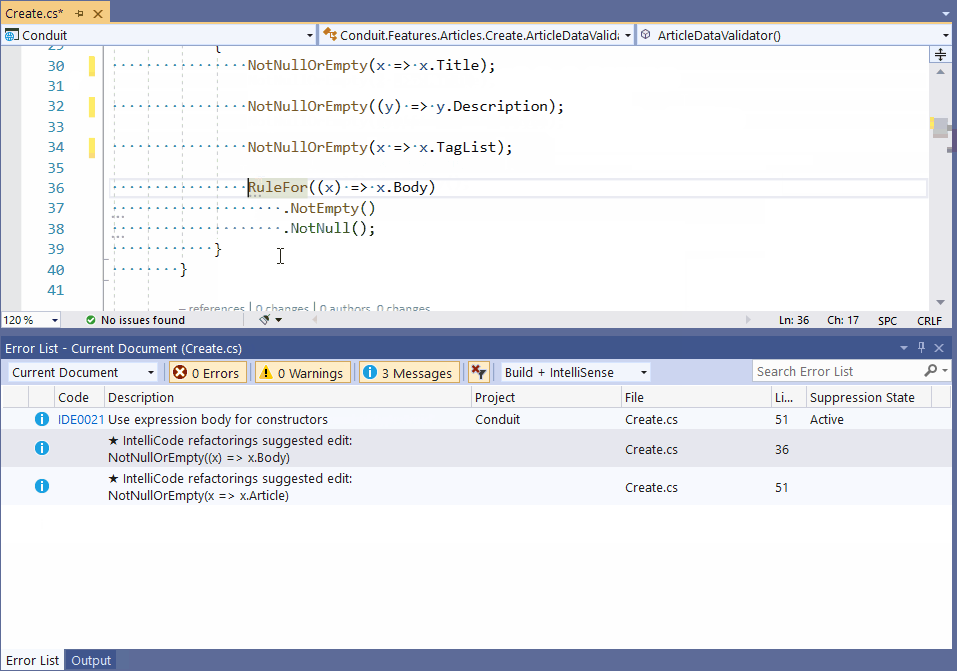
- ANI uygulamalarının kalitelerinin arttırılması ve doğru veri ile beslenmeleri için yazılım takımı (ya da IT takımı) içerisinde (özellikle konfigürasyon yönetimi kısmında) yeni roller/görev tanımları oluşmaya başlayacak.
- Kod gözden geçirme aşamasında (code review) chatbotlar (ya da asistanlar) devreye girecekler. Belki çok akıllı olmayacaklar ama çalıştığınız alanın (geliştirilen projenin) iş kavramlarına (Örneğin; hava yolu, finans, e-ticaret, moda vb.), sistem gereksinimlerine, mimari desenlere, tasarım kalıplarına ve yazılım kalite ölçütlerine göre bizi yönlendirecekler.
- Yazılım gereksinimlerinin çok net olması gerekliliği ANI uygulamaları için handikap olmaya devam edecek. Gereksinimler arasındaki ilişkilerin karmaşık olması, bu gereksinimlerin %100 çözümlenmelerini zorlaştıracak.
Not: Eğer yazılım gereksinimlerinin de ANI sistemleriyle oluşturulması sağlanırsa (ya da doğrulama yapılabilirse), bu sorun da %100 olmasa da aşılabilir.
- Derin öğrenme modellerinin eğitilmesinde gizlilik ve erişilebilirlik problemleri devam edecek. Firmalar kendi kaynak kodlarını derin öğrenme modellerinin eğitimi için paylaşmak istemeyecekler. Açık kaynak kod kullanımlarının yaygınlaşması bu soruna bir derece çare olabilecek.
- Otomatik kod oluşturulmasına ek olarak otomatik (ve akıllı) API üretimi yapılabilecek ve uygulamalar hızlıca ayağa kalkabilecek.
- ANI uygulamaları yazılımcılara yardımcı olacak ancak bu durum, bilgisayar mimarisi, işletim sistemi yapısı/tasarımı, veri yapıları, algoritma analizi, programlama dili tasarımı ve yazılım tasarımı/mimarisi bilgilerine derinlemesine sahip yazılımcıları (çok) daha kıymetli hale getirecek.
- Peki oyunu ne bozabilir? “Quantum computing”
Kaynaklar
- Nye, M., Hewitt, L., Tenenbaum, J., & Solar-Lezama, A. (2019). Learning to infer program sketches. arXiv preprint arXiv:1902.06349.
- Yucalar, F., Ozcift, A., Borandag, E., & Kilinc, D. (2019). Multiple-classifiers in software quality engineering: Combining predictors to improve software fault prediction ability. Engineering Science and Technology, an International Journal.
- Borandag, E., Ozcift, A., Kilinc, D., & Yucalar, F. (2019). Majority vote feature selection algorithm in software fault prediction. Computer Science and Information Systems, 16(2), 515–539.
- BOZYİĞİT, F., AKTAŞ, Ö., & Kilinc, D. (2019). Automatic concept identification of software requirements in Turkish. Turkish Journal of Electrical Engineering & Computer Sciences, 27(1), 453–470.
- Devlin, J., Uesato, J., Bhupatiraju, S., Singh, R., Mohamed, A. R., & Kohli, P. (2017, August). Robustfill: Neural program learning under noisy I/O. In Proceedings of the 34th International Conference on Machine Learning-Volume 70 (pp. 990–998). JMLR. org.
- Balog, M., Gaunt, A. L., Brockschmidt, M., Nowozin, S., & Tarlow, D. (2016). Deepcoder: Learning to write programs. arXiv preprint arXiv:1611.01989.
- Yücalar, F., Kilinc, D., Borandag, E., & Ozcift, A. (2016). Regression analysis based software effort estimation method. International Journal of Software Engineering and Knowledge Engineering, 26(05), 807–826.
- Zaremba, W., Mikolov, T., Joulin, A., & Fergus, R. (2016, June). Learning simple algorithms from examples. In International Conference on Machine Learning (pp. 421–429).
- Kılınç, D., Yücalar, F., Borandağ, E., & Aslan, E. (2016). Multi‐level reranking approach for bug localization. Expert Systems, 33(3), 286–294.
- Ekici, S. K., Oturgan, A., Kılınç, D., & Araz, C. (2016). Software Requirements Prioritization: A Case Study. In International Conference on Computer Science and Engineering (pp. 1–6).
- Neelakantan, A., Le, Q. V., & Sutskever, I. (2015). Neural programmer: Inducing latent programs with gradient descent. arXiv preprint arXiv:1511.04834.
- Kılınç, D., Borandağ, E., Yücalar, F., Özçift, A., & Bozyiğit, F. (2015). Yazılım Hata Kestiriminde Kolektif Sınıflandırma Modellerinin Etkisi. IX Ulusal Yazılım Mühendisliği Sempozyumu, Yaşar Üniversitesi, Bornava-İzmir, 9–11.
- Kilinç, D., Bozyigit, F., Özçift, A., Yücalar, F., & Borandag, E. (2015). Metin Madenciliği Kullanılarak Yazılım Kullanımına Dair Bulguların Elde Edilmesi. In UYMS.
- Bozyiğit, F., Kılınç, D., Kut, A., & Kaya, M. (2015). Bulanık Mantık Algoritmaları Kullanarak Kaynak Kod Benzerliği Bulma. XVII. Akademik Bilişim Konferansı–Ab.
- Kılınç, D., Borandağ, E., Yücalar, F., Özçift, A., & Bozyiğit, F. (2015). Yazılım Hata Kestiriminde Kolektif Sınıflandırma Modellerinin Etkisi. IX Ulusal Yazılım Mühendisliği Sempozyumu, Yaşar Üniversitesi, Bornava-İzmir, 9–11.
- Yücalar, F., & Borandağ, E. Determining the Tested Classes with Software Metrics. Celal Bayar Üniversitesi Fen Bilimleri Dergisi, 13(4), 863–871.
- Borandag, E., Yucalar, F., & Erdogan, S. Z. (2016). A case study for the software size estimation through MK II FPA and FP methods. International Journal of Computer Applications in Technology, 53(4), 309–314.
- Braz, M. R., & Vergilio, S. R. (2006, September). Software effort estimation based on use cases. In 30th Annual International Computer Software and Applications Conference (COMPSAC’06) (Vol. 1, pp. 221–228). IEEE.
- https://devblogs.microsoft.com/visualstudio/ai-assisted-developer-tools/